생성형 AI의 개요와 활용
생성형 AI는 텍스트, 이미지, 음악 등 다양한 형태의 창작물을 만들어 내는 인공지능 기술로, 딥러닝의 한 분야에 속합니다. 사용자가 원하는 정보나 스타일을 주면 그에 맞춰 새 콘텐츠를 자동으로 생성하는 방식으로 작동합니다. 머신러닝·딥러닝이 주로 분석·예측에 초점을 둔 반면, 생성형 AI는 창작을 목표로 해 AI 기술의 새로운 차원을 열고 있습니다.
💡 이런 분들께 추천합니다
- 생성형 AI를 처음 접하는 분
- 텍스트·이미지·동영상 생성 모델을 한 번에 파악하고 싶은 분
- 업무·서비스에 생성형 AI를 도입하려는 기획자·개발자
🧩 개념 설명 / 배경 지식
이미 생성형 AI 정의와 프롬프트 기반 생성에 익숙하다면 다음 섹션으로 넘어가도 됩니다.
생성형 AI
기존 데이터를 학습해 사용자가 제공하는 프롬프트(prompt)에 따라 결과물을 만듭니다. 텍스트, 이미지, 동영상, 음악 등을 생성할 수 있으며, 과거에는 AI가 전문가 영역이었다면 지금은 일반 사용자도 쉽게 활용할 수 있는 환경이 되었습니다.
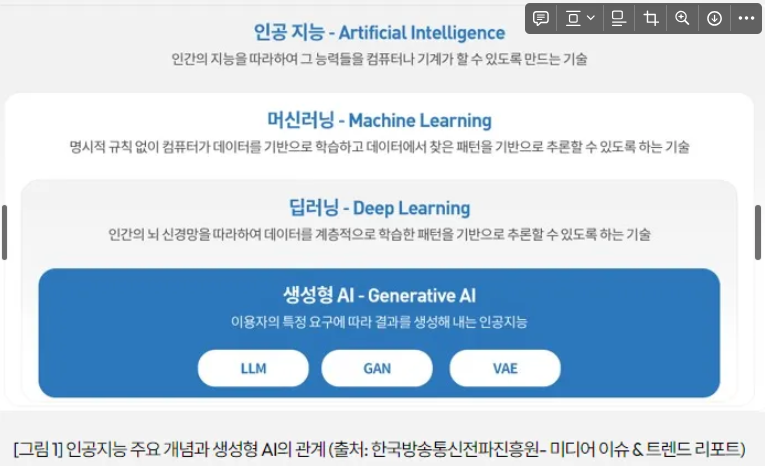
🔍 본론: 생성형 AI의 주요 분야와 모델
1. 텍스트 생성형 AI
자연어 처리(NLP) 기반으로 프롬프트에 따라 글을 생성합니다.
| 제공처 | 대표 모델 | 특징 |
|---|---|---|
| OpenAI | GPT-3.5, GPT-4 | 자연어 이해·텍스트 생성, 대화형 앱 |
| Anthropic | Claude 3 Haiku, Opus | 인간 중심 설계, 대화 모델 |
| PaLM | Bard AI 기반 | |
| Meta | LLaMA 시리즈 | 오픈소스, 자체 학습·맞춤화 |
| 기타 | Cohere, Gopher, GPT-NeoX | NLP·요약·오픈소스 |
2. 이미지 생성형 AI
텍스트 설명을 바탕으로 이미지를 생성합니다.
- OpenAI DALL·E 3: 텍스트 기반 이미지 생성, 정교한 결과
- MidJourney: 예술적 이미지
- Stable Diffusion: 오픈소스, 다양한 작업
- Google Imagen 2: 고해상도
- Adobe Firefly: 이미지 생성·편집
- Artbreeder: GAN 기반 스타일 조정
3. 동영상·멀티모달 생성형 AI
- 동영상: Runway Gen-2, Meta Make-A-Video, Pika Labs, Imagen Video, Stable Video Diffusion, Synthesia, DeepBrain AI 등
- 멀티모달(텍스트·이미지·동영상·오디오 통합): GPT-4V, Claude 3, Google Gemini, Perceiver, ImageBind, Kosmos-1, Flamingo 등
⚠️ 주의사항
- 생성형 AI 결과물의 저작권·상업 이용 조건은 모델·서비스마다 다르므로, 활용 전 이용 약관과 라이선스를 확인하세요.
- 환각(hallucination)이나 편향이 있을 수 있으므로, 중요한 결정·정보 배포 전 검증이 필요합니다.
✅ 실습 / 적용 예시
이 글은 개요와 분류에 초점을 둡니다. 실제로 써 보려면 ChatGPT, Claude, Gemini 등 대화형 도구나, AI Tools 검색 사이트에서 용도에 맞는 도구를 골라 사용해 보시면 좋습니다.
🚧 트러블슈팅 / 자주 묻는 질문
Q. 생성형 AI와 기존 ML/딥러닝의 차이는?
A. 기존 ML·딥러닝은 주로 분류·예측·패턴 분석에 쓰이고, 생성형 AI는 새 콘텐츠 생성(글, 이미지, 영상, 음악 등)에 특화되어 있습니다.
Q. 어떤 생성형 AI 도구를 골라야 할까요?
A. 용도(텍스트/이미지/영상), 비용, API 제공 여부, 데이터 보안 요구사항에 따라 다릅니다. AIXploria AI Tools에서 카테고리별로 검색해 보실 수 있습니다.
📝 마무리
- 생성형 AI는 텍스트·이미지·동영상·멀티모달 등 분야별로 다양한 모델과 서비스가 있습니다.
- 접근성 확대로 비전공자도 쉽게 활용할 수 있으며, 업무 자동화·고객 서비스·교육·엔터테인먼트 등에 쓰이고 있습니다.
- 다음에는 프롬프트 엔지니어링, RAG, 이미지 생성(확산 모델) 등 심화 주제를 이어서 학습해 보시면 좋습니다.
참고자료

댓글 남기기