LLM 구동을 위한 GPU 메모리 계산 완벽 가이드 (Can it Run LLM? 도구 포함)
LLM을 실제로 서비스하려면 GPU 메모리 요구량을 정확히 아는 것이 필수입니다. 메모리가 부족하면 OOM으로 서비스가 끊기고, 과도하게 잡으면 비용만 늘어납니다. 이 글에서는 필요 GPU 메모리 계산 공식, 정밀도·오버헤드 이해, 최적화 기법, 그리고 “내 GPU로 이 LLM을 돌릴 수 있을까?”를 확인하는 방법까지 다룹니다.
💡 이런 분들께 추천합니다
- LLM 배포·면접에서 GPU 메모리 질문을 준비하는 분
- A100·RTX 등 보유 GPU로 어떤 모델을 돌릴 수 있을지 알고 싶은 분
- 양자화·오프로딩 등 메모리 최적화를 적용하려는 분
🧩 개념 설명 / 배경 지식
GPU 메모리와 LLM
모델 파라미터(가중치), 활성화, KV 캐시 등이 모두 GPU 메모리를 사용합니다. 파라미터 수(P), 파라미터당 비트(Q), 오버헤드 계수로 필요 메모리를 추정할 수 있습니다. 이미 계산 공식에 익숙하다면 다음 섹션으로 넘어가도 됩니다.
🔍 본론: GPU 메모리 계산과 최적화
GPU 메모리 계산, 왜 정확해야 할까?
LLM을 위한 GPU 메모리 계산이 중요한 이유는 크게 세 가지로 요약할 수 있습니다.
- 성능 및 안정성 확보: GPU 메모리는 모델의 파라미터(가중치), 활성화(activations), KV 캐시 등 추론 과정에 필요한 모든 데이터를 저장하는 공간입니다. 필요한 메모리 양을 정확히 예측하지 못하면 ‘메모리 부족(Out of Memory, OOM)’ 오류가 발생하여 서비스가 중단될 수 있습니다. 안정적인 LLM 서비스를 위해서는 충분한 메모리 확보가 선결 과제입니다.
- 비용 효율성: 고성능 GPU는 매우 고가입니다. 특히 A100, H100과 같은 데이터센터용 GPU는 개당 수천만 원을 호가합니다. 필요한 메모리 양을 정확히 계산하면, 과도한 사양의 GPU를 불필요하게 구매하거나 임대하는 비용을 절감할 수 있습니다. 반대로 너무 낮은 사양을 선택하여 반복적으로 업그레이드하는 것 또한 비효율적입니다.
- 배포 전략 수립: 계산된 메모리 요구량은 단일 GPU로 충분한지, 아니면 여러 GPU를 사용해야 하는지(모델 병렬화 등) 결정하는 기준이 됩니다. 이는 전체 시스템 아키텍처 설계와 배포 전략에 직접적인 영향을 미칩니다. 예를 들어, 168GB 메모리가 필요한 모델을 80GB GPU로 구동하려면 최소 2대의 GPU가 필요하며, 이를 위한 분산 처리 기술(예: Tensor Parallelism, Pipeline Parallelism) 적용을 고려해야 합니다.
GPU 메모리 계산 공식
LLM 추론에 필요한 GPU 메모리를 추정하는 기본적인 공식은 다음과 같습니다.
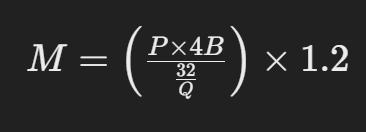
- M 은 기가바이트 단위의 GPU 메모리입니다.
- P (모델 파라미터 수): 모델의 크기를 나타내는 가장 중요한 지표입니다. 예를 들어 LLaMA 7B 모델은 약 70억(7 Billion)개의 파라미터를, GPT-3는 1750억(175 Billion)개의 파라미터를 가집니다. 모델의 파라미터 수는 일반적으로 모델 이름에 포함되거나 관련 논문, 모델 카드(Hugging Face 등)에서 확인할 수 있습니다. 파라미터는 모델이 학습 데이터로부터 학습한 가중치(weights)와 편향(biases) 값들을 의미하며, 모델의 지식과 능력을 저장하는 핵심 요소입니다.
- 4B는 매개변수당 사용되는 4바이트를 나타냅니다.
- Q (파라미터당 비트 수): 모델의 가중치를 로드할 때 사용하는 데이터 정밀도(Precision)를 비트 단위로 나타냅니다. 이는 파라미터 하나를 저장하는 데 몇 비트가 사용되는지를 의미합니다.
- 32비트 (FP32, Single Precision): 파라미터당 4바이트(32 bits / 8 bits/byte = 4 bytes)를 사용합니다. 가장 높은 정밀도를 제공하지만, 메모리 사용량과 계산량이 가장 큽니다.
- 16비트 (FP16, Half Precision): 파라미터당 2바이트(16 / 8 = 2 bytes)를 사용합니다. 메모리 사용량을 절반으로 줄이고 계산 속도를 높일 수 있어 LLM 추론에 널리 사용됩니다. 약간의 정밀도 손실이 발생할 수 있지만, 대부분의 경우 LLM 성능에 큰 영향을 미치지 않습니다.
- BF16 (BFloat16): 역시 파라미터당 2바이트를 사용합니다. FP16과 유사하지만 지수부 비트가 더 많아 다이나믹 레인지는 FP32와 유사하게 유지하면서 가수부 비트를 줄여 메모리를 절약합니다. 특히 학습 과정에서 안정성이 높아 Google TPU 등에서 선호됩니다. 추론 시에도 사용될 수 있습니다.
- 8비트 정수 (INT8): 파라미터당 1바이트(8 / 8 = 1 byte)를 사용합니다. 메모리 사용량을 크게 줄이고 정수 연산을 통해 추론 속도를 높일 수 있습니다. 하지만 FP16/BF16보다 정밀도 손실이 클 수 있어, 양자화(Quantization) 기법을 신중하게 적용해야 합니다.
- 4비트 정수 (INT4): 파라미터당 0.5바이트(4 / 8 = 0.5 bytes)를 사용합니다. 극단적인 메모리 절약이 가능하지만, 상당한 정밀도 손실을 감수해야 할 수 있습니다. GPTQ, AWQ 등 정밀도 손실을 최소화하는 고급 양자화 기법과 함께 사용됩니다.
- 오버헤드 (Overhead, 일반적으로 1.2 ~ 1.5): 모델 파라미터 자체를 저장하는 메모리 외에 추가적으로 필요한 메모리 공간을 고려하기 위한 계수입니다. 이 오버헤드에는 다음과 같은 요소들이 포함됩니다.
- 활성화 (Activations): 모델이 입력을 처리하는 과정에서 각 레이어의 중간 계산 결과값입니다. 입력 시퀀스의 길이, 배치 크기, 모델 구조에 따라 필요한 메모리 양이 달라집니다.
- KV 캐시 (Key-Value Cache): Transformer 기반 모델(대부분의 LLM)에서 어텐션 메커니즘의 효율성을 높이기 위해 이전 토큰들의 Key와 Value 벡터를 저장하는 공간입니다. 특히 긴 텍스트를 생성할 때 메모리 사용량이 크게 증가할 수 있습니다.
- 임시 버퍼 (Temporary Buffers): 연산 과정에서 임시 데이터를 저장하기 위한 공간입니다.
- 소프트웨어 오버헤드: 모델 로딩 및 실행을 위한 라이브러리(PyTorch, TensorFlow 등), CUDA 커널 등이 차지하는 메모리입니다.
- 일반적으로 20%의 오버헤드(곱하기 1.2)를 가정하는 경우가 많지만, 이는 최소한의 추정치입니다. 실제로는 배치 크기, 시퀀스 길이, 사용하는 추론 최적화 기법 등에 따라 더 많은 오버헤드가 필요할 수 있으며, 안정적인 운영을 위해서는 1.3 ~ 1.5 정도의 계수를 고려하는 것이 좋습니다.
계산 예시: LLaMA 70B 모델 (16비트 정밀도)
실제 예시를 통해 계산 과정을 살펴보겠습니다. 700억(70 Billion)개의 파라미터를 가진 LLaMA 모델을 16비트(FP16) 정밀도로 로드하여 추론한다고 가정해 봅시다.
- 모델 파라미터 수 (P): 70,000,000,000 개
- 파라미터당 비트 수 (Q): 16 비트
- 파라미터당 바이트 수: 32/16= 2 바이트
- 모델 파라미터 저장에 필요한 기본 메모리: 140,000,000,000 바이트 이를 기가바이트(GB)로 변환하면 (1 GB = 1024^3 바이트 ≈ 10억 바이트): 140,000,000,000 바이트 / (1024^3 바이트/GB) ≈ 130.2 GB (계산 편의상 1 GB = 10^9 바이트로 근사하면 140 GB) 원본 글의 계산 방식(1GB=10^9 바이트 근사)을 따라 140GB로 진행하겠습니다.
- 오버헤드 적용 (20% 가정, 계수 1.2): 필요 총 GPU 메모리 ≈ 140 GB × 1.2 = 168 GB
이 계산에 따르면, LLaMA 70B 모델을 FP16 정밀도로 안정적으로 추론하기 위해서는 약 168GB의 GPU 메모리가 필요합니다.
실제적인 의미와 하드웨어 고려 사항
위 계산 결과(168GB)는 중요한 시사점을 던져줍니다. 현재 시중에서 가장 강력한 데이터센터용 GPU 중 하나인 NVIDIA A100 또는 H100의 80GB 모델 한 대로는 LLaMA 70B 모델을 FP16으로 구동하기에 메모리가 부족합니다.
따라서 다음과 같은 하드웨어 구성을 고려해야 합니다.
- 다중 GPU 사용: 최소 2대의 80GB GPU (예: A100 80GB SXM) 또는 그 이상의 메모리를 가진 GPU(예: H100 80GB) 여러 대를 사용해야 합니다. 이 경우, 모델의 가중치를 여러 GPU에 분산시키는 모델 병렬화(Model Parallelism) 기술(예: Tensor Parallelism, Pipeline Parallelism)이 필요합니다. NVLink와 같은 고속 인터커넥트 기술은 GPU 간 통신 속도를 높여 성능 저하를 최소화하는 데 도움이 됩니다.
- 고용량 메모리 GPU: NVIDIA H100 NVL (94GB * 2 = 188GB)과 같이 단일 노드에서 더 큰 메모리를 제공하는 솔루션도 고려할 수 있습니다.
- 소비자용 GPU의 한계: NVIDIA GeForce RTX 4090 (24GB)이나 RTX 3090 (24GB)과 같은 고성능 소비자용 GPU도 있지만, LLaMA 70B와 같은 거대 모델을 단일 GPU로 구동하기에는 메모리가 턱없이 부족합니다. 더 작은 모델(예: 7B, 13B)이나, 후술할 메모리 최적화 기법을 적극적으로 활용해야 합니다.
- 클라우드 GPU 활용: 직접 하드웨어를 구축하기 어렵다면 AWS (EC2 P4, P5 인스턴스), Google Cloud (A2, A3 VM), Microsoft Azure (ND, NC 시리즈) 등 클라우드 서비스 제공업체의 고용량 GPU 인스턴스를 임대하여 사용하는 것이 현실적인 대안이 될 수 있습니다.
LLM 배포를 위한 메모리 사용 최적화 기법
필요한 GPU 메모리 요구량을 줄여 하드웨어 비용을 절감하고 더 작은 GPU에서도 LLM을 실행할 수 있도록 돕는 다양한 최적화 기법들이 존재합니다.
- 양자화 (Quantization):
- 모델의 가중치와 활성화 값의 데이터 타입을 FP32나 FP16보다 더 적은 비트(예: INT8, INT4)로 표현하는 기술입니다.
- 메모리 절약: 파라미터당 바이트 수를 줄여(INT8은 1바이트, INT4는 0.5바이트) 모델 로딩에 필요한 메모리를 크게 감소시킵니다. 예를 들어, FP16(2바이트) 모델을 INT8(1바이트)로 양자화하면 파라미터 저장 메모리가 절반으로 줄어듭니다.
- 추론 속도 향상: 정수 연산은 부동소수점 연산보다 빠른 경우가 많아 추론 속도 개선 효과도 기대할 수 있습니다.
- 정밀도 손실: 비트 수를 줄이는 과정에서 정보 손실이 발생하여 모델 성능(정확도)이 약간 저하될 수 있습니다. 이를 최소화하기 위해 PTQ(Post-Training Quantization), QAT(Quantization-Aware Training), 그리고 GPTQ, AWQ, SmoothQuant와 같은 고급 양자화 알고리즘이 개발되었습니다.
- 모델 가지치기 (Pruning) 및 희소성(Sparsity) 활용:
- 모델 성능에 거의 영향을 미치지 않는 불필요한 가중치(파라미터)를 제거하여 모델 크기를 줄이는 기법입니다.
- 희소 모델(Sparse Model)은 많은 가중치 값이 0인 모델을 의미하며, 이를 효율적으로 저장하고 계산하는 하드웨어 및 소프트웨어 지원(예: NVIDIA Ampere 아키텍처의 Sparse Tensor Core)이 있다면 메모리 및 속도 이점을 얻을 수 있습니다.
- 지식 증류 (Knowledge Distillation):
- 크고 강력한 ‘교사 모델(Teacher Model)’의 지식을 작고 가벼운 ‘학생 모델(Student Model)’에게 전달하여 학습시키는 기법입니다.
- 학생 모델은 교사 모델보다 훨씬 적은 파라미터를 가지므로 메모리 요구량이 적지만, 교사 모델과 유사한 성능을 내도록 학습됩니다.
- 효율적인 어텐션 메커니즘 (Efficient Attention Mechanisms):
- Transformer 모델의 핵심인 어텐션 계산은 시퀀스 길이가 길어질수록 메모리 사용량(특히 KV 캐시)과 계산량이 제곱으로 증가하는 문제가 있습니다.
- FlashAttention, PagedAttention 등의 최적화된 어텐션 구현은 메모리 사용량을 줄이고 계산 속도를 높여 더 긴 시퀀스를 효율적으로 처리할 수 있게 돕습니다. 특히 PagedAttention은 vLLM과 같은 추론 서버에서 KV 캐시 메모리를 효율적으로 관리하는 데 사용됩니다.
- 모델 오프로딩 (Model Offloading):
- GPU 메모리가 부족할 경우, 모델의 일부 레이어나 사용 빈도가 낮은 파라미터를 CPU RAM이나 심지어 NVMe SSD와 같은 저장 장치로 옮겨두고, 필요할 때만 GPU 메모리로 로드하는 방식입니다.
- 추론 속도는 느려지지만, 가용 GPU 메모리보다 큰 모델을 실행할 수 있게 해줍니다.
accelerate라이브러리 등이 이 기능을 지원합니다.
“Can it Run LLM?” - 내 GPU로 가능할까? 확인 방법
특정 LLM을 자신의 GPU 환경에서 실행할 수 있는지 확인하는 가장 확실한 방법은 앞서 설명한 메모리 계산 공식을 직접 적용해보는 것입니다. 아래 웹사이트를 통해 접속하실수 있습니다. https://huggingface.co/spaces/Vokturz/can-it-run-llm
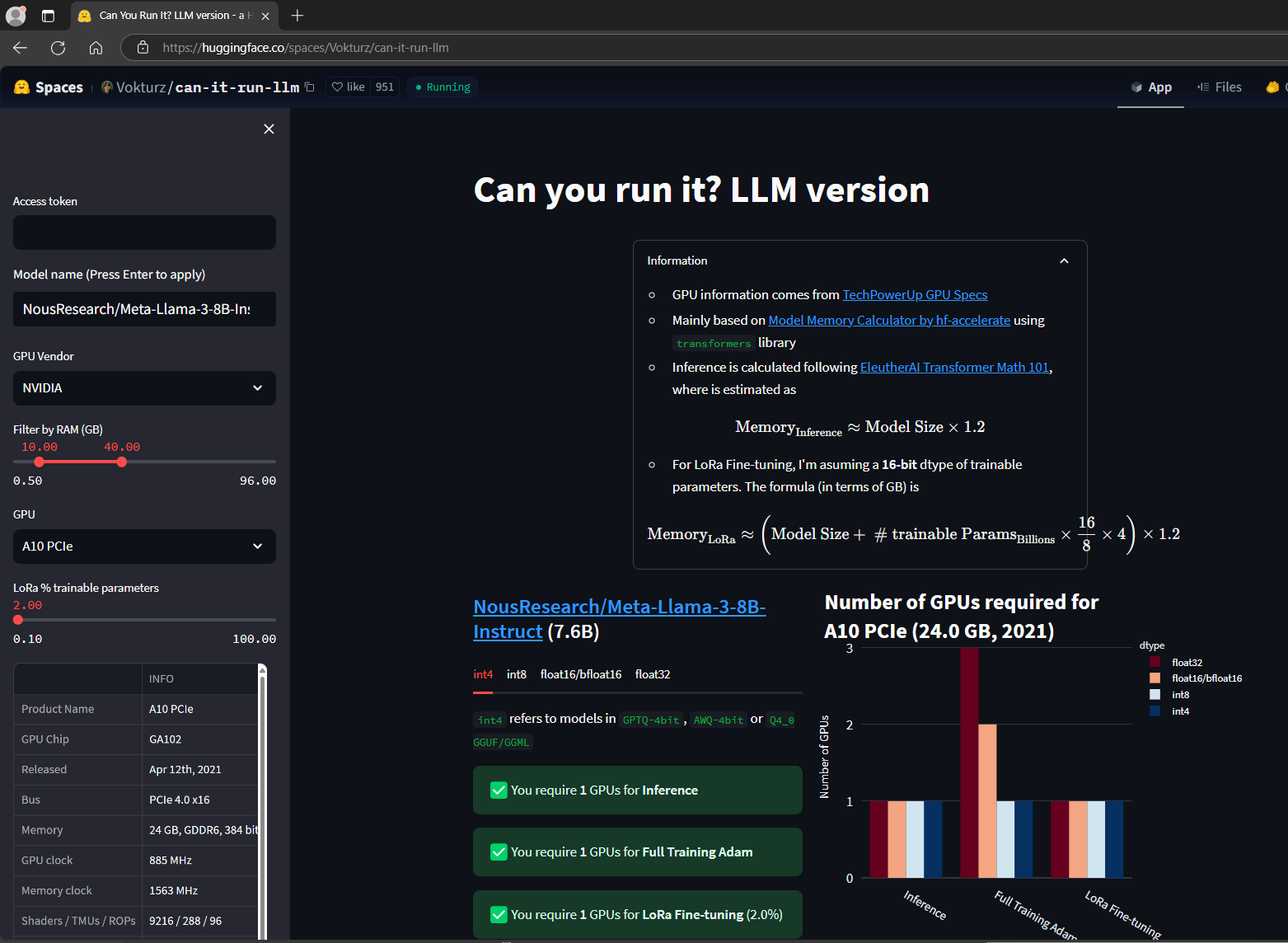
- 모델 정보 확인: 실행하려는 LLM의 파라미터 수(P)를 확인합니다. (예: Hugging Face 모델 카드, 관련 논문)
- 정밀도(Q) 결정: 어떤 정밀도(FP16, INT8, INT4 등)로 모델을 로드할지 결정합니다. 이는 사용하려는 추론 라이브러리나 프레임워크가 지원하는 옵션에 따라 달라질 수 있습니다.
- 메모리 계산: 공식을 사용하여 필요한 최소 GPU 메모리를 추정합니다.
(P * (Q / 8)) * 1.2(또는 더 보수적인 오버헤드 계수 사용) - 내 GPU 사양 확인: 사용하려는 GPU의 VRAM(Video RAM) 용량을 확인합니다. (NVIDIA GPU는
nvidia-smi명령어로 확인 가능) - 비교: 계산된 필요 메모리 양과 내 GPU의 VRAM 용량을 비교합니다.
- VRAM ≥ 필요 메모리: 해당 정밀도로 모델을 로드하고 실행할 가능성이 높습니다. (단, 실제 구동 시 배치 크기, 시퀀스 길이 등 다른 요인에 따라 메모리 사용량이 달라질 수 있습니다.)
- VRAM < 필요 메모리: 해당 정밀도로는 모델을 실행하기 어렵습니다. 더 낮은 정밀도(예: INT8, INT4 양자화)를 사용하거나, 모델 오프로딩, 더 작은 모델 사용 등을 고려해야 합니다.
⚠️ 주의사항
- 오버헤드 1.2는 최소 추정입니다. 배치 크기·시퀀스 길이·KV 캐시에 따라 1.3~1.5를 쓰는 것이 안정적일 수 있습니다. 실제로는 한 번 돌려 보며 여유를 두는 것이 좋습니다.
- 양자화(INT8/INT4)는 메모리를 줄이지만 정확도가 떨어질 수 있으므로, 용도에 맞게 품질을 확인하세요.
✅ 실습 / 적용 예시
Step 1. Can it Run LLM?에서 모델·정밀도·GPU를 선택해 필요 메모리를 확인합니다.
Step 2. nvidia-smi로 보유 GPU VRAM을 확인한 뒤, 계산된 필요 메모리와 비교합니다.
Step 3. 부족하면 양자화·작은 모델·오프로딩을 적용하거나, vLLM·TGI 등 추론 서버의 메모리 최적화 옵션을 검토합니다.
🚧 트러블슈팅 / 자주 묻는 질문
Q. 계산한 메모리보다 GPU가 작은데요.
A. INT8/INT4 양자화, 더 작은 모델, 모델 오프로딩(CPU·디스크 활용), 배치 크기·시퀀스 길이 축소를 순서대로 고려해 보세요.
Q. LLaMA 70B는 몇 GB GPU가 필요하나요?
A. FP16 기준 파라미터만 약 140GB, 오버헤드 1.2 적용 시 약 168GB입니다. 80GB GPU 2대 이상 또는 H100 NVL 등 고용량 GPU를 고려해야 합니다.
📝 마무리
- 필요 GPU 메모리는 파라미터 수(P), 정밀도(Q), 오버헤드로 추정하며, 안정 운영을 위해 여유 계수를 두는 것이 좋습니다.
- 양자화·효율적 어텐션·오프로딩 등으로 제한된 자원에서도 LLM을 구동할 수 있습니다.
- “Can it Run LLM?” 도구와 직접 계산을 함께 사용해, 프로덕션 설계와 면접 준비에 활용해 보시면 됩니다.
댓글남기기