ElasticSearch 살펴보기 - Index
ElasticSearch 살펴보기 - Index
Index 구성
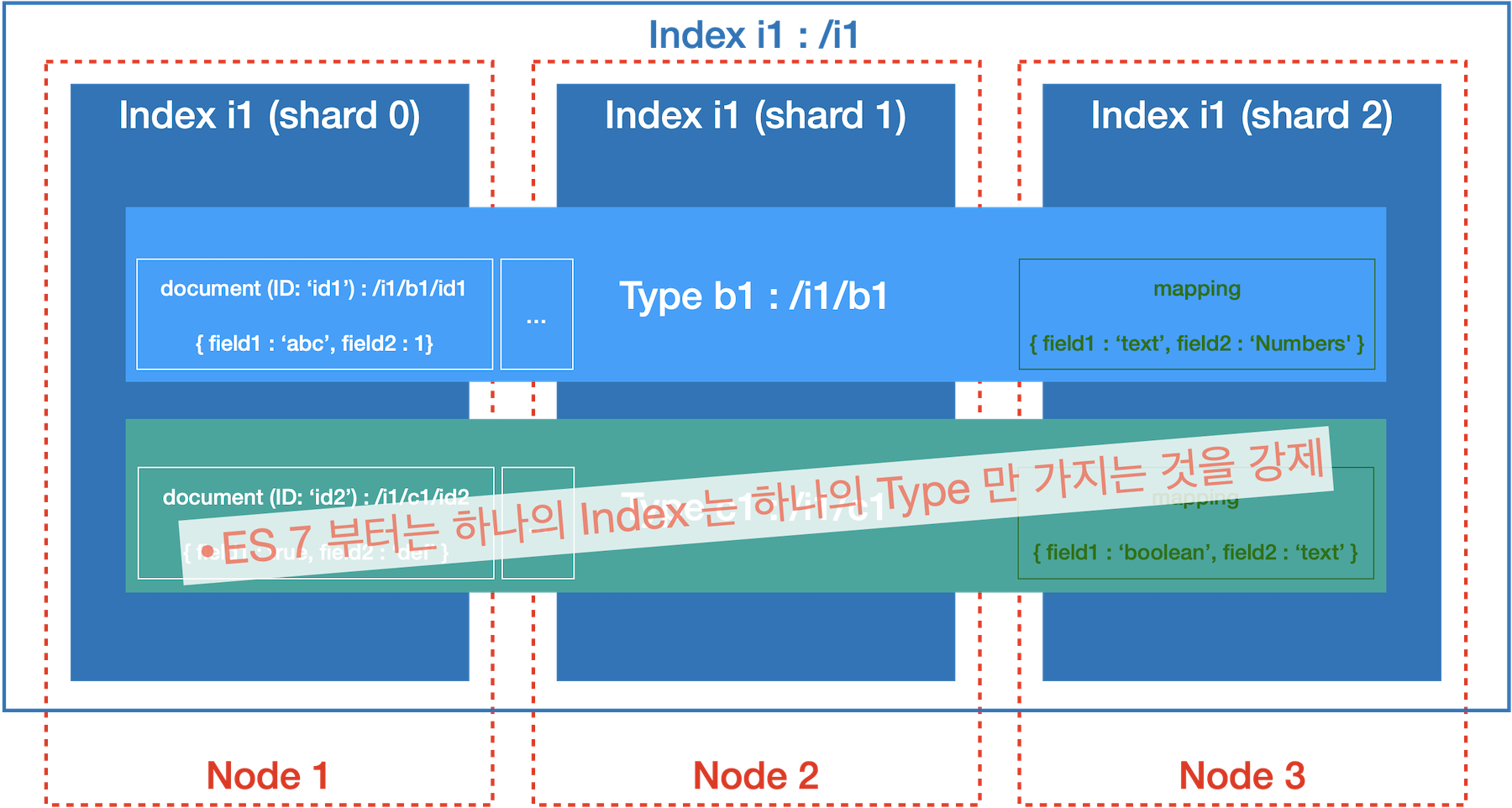
Index
- 하나 이상의 Type 을 포함 (ES 7 이하)
- RDB 에서 Database 역할
- ES 7 부터는 하나의 Index 는 하나의 Type 만 가지는 것을 강제
Type (ES < 7)
- 문서의 종류
- RDB 에서 Table 역할
Mapping
- 문서 내 모든 field 에 대한 정의
- field 의 데이터 유형에 대한 정보
- mapping 에 정의되지 않은 field 가 새로 추가될 때, ElasticSearch 는 field 의 데이터 타입을 추측해서 mapping 에 추가
- mapping 이 정의된 이후, 해당 field 에는 mapping 에 맞는 데이터만 저장 가능
Shard
- 하나의 Index 는 여러개의 shard 로 나뉨
- shard 는 여러 Node 에 분산 저장, Node 간 이동
- 확장성, 가용량을 위한 역할
Document
- Index 를 구성하는 최소 데이터 단위
- 검색되는 최소 단위
- RDB 에서 Table 에 저장된 하나의 Row
- 문서는 필드(field)와 값(ElasticSearch Denver) 로 구성
- 문서는 Json 으로 표현
- Schema-free 처럼 사용가능한 것처럼 보이지만, Type의 mapping 에 각 문서의 schema 가 존재
Index 생성/운영 권장 방식
- schemaless 기능은 사용하지 말것
- auto-mapping 을 사용하지 말것
- 권장 설정
action.auto_create_index = false. # 자동 인덱스 생성 방지 Index.mapper.dynamic = false # 컬럼이 자동매핑 되는 것 방지
REST 방식의 인덱스 생성/설정
문서 등록 (index, type, mapping 을 함께 생성)
curl -X GET -H 'content-type: application/json' 'http://localhost:9200/{index-name}/{type-name}/{문서ID}' -d { 문서JSON }
문서 조회
curl -X GET 'localhost:9200/{index-name}/{type-name}/{문서ID}'
Index 만 생성
curl -X PUT 'localhost:9200/{index-name}'
Index 의 mapping 조회
curl -X GET 'localhost:9200/{index-name}/_mapping/{type-name}?pretty'
curl -X GET 'localhost:9200/{index-name}/{type-name}/_mapping/{type-name}?pretty'
Index 에서 문서 검색
curl -X GET 'localhost:9200/{index-name목록 ,로 구분}/{type-name목록 ,로 구분}/_search?q={검색keyword}&field={검색대상field목록 ,로 구분}&size=1&pretty'
curl -X GET 'localhost:9200/{index-name목록 ,로 구분}/{type-name목록 ,로 구분}/_search?q={검색keyword}&field={검색대상field목록 ,로 구분}&size=1&pretty' -d '{
“query”: {
“query_string”: “elastic search san francisco”,
“default_field”: “name”,
“default_operator”: “AND”,
}
}
Index 에서 지원하는 데이터 타입
| data type | |||
|---|---|---|---|
| keyword | - 분석기 거치지 않음 - 원문 그대로 색인 - 검색 필터링/정렬/집계가 필요한 항목 | 옵션 - boost : 검색/정렬 가중치 - doc_values : 메모리 캐시에 로드할지 여부 (default : true) - index : 검색에 사용할지 여부 (default : true) - null_value : 값이 없을때 필드 생성할지 | - … |
| text | - (형태소)분석기를 거쳐 전문검색이 가능 | 옵션 - analyzer : 분석기 지정 - boost : 검색/정렬 가중치 - fielddata : 정렬/집계 등에서 메모리 캐시 사용여부 (default : false) - index : 검색에 사용할지 여부 (default : true) - … | |
| array | - 문자, 숫자, 객체 배열 - 하나의 array 필드에는 동일한 타입의 데이터가 저장되어야함 - array 타입을 명시적으로 mapping 에 정의하지 않는다. (ES 모든 필드는 다수의 값을 저장할 수 있기 때문) - array 데이터 전체 범위에 대해 OR 조건으로 검색 | ||
| numeric | - long, integer, short, byte, double, float, half_float | ||
| date | - yyyyMMddHHmmss 등으로 표현 (default: yyyy-MM-ddTHH:mm:ssZ) - ES 는 date 타입을 내부적으로 UTC 밀리초로 변환하여 저장 | ||
| range | - 범위가 있는 데이터 - integer_range, float_range, long_range, double_range, date_range, ip_range | ||
| boolean | true, false 값 저장 | ||
| geo-point | - 위도, 경도 데이터 저장 - 위치기반 쿼리/집계/정렬에 활용 가능 | ||
| ip | - IPv4, IPv6 | ||
| object | - 다른 문서를 포함하는 형식 - ‘object’ 키워드를 사용하여 mapping 을 정의하지 않음 - 필드 값으로 다른 문서구조를 입력하는 형태로 필드 정의 | PUT test/_mapping/_doc/1 { “properties”: { “companies”: { “properties”: { /* object 타입 필드 정의 */ “name”: { “type”: text } } } } } | |
| nested | - 다른 문서의 배열을 포함하는 형식 - ‘nested’ 키워드를 사용하여 mapping 을 정의하지 않음 - 필드 값으로 다른 문서구조를 배열 형태로 입력하는 형태로 필드 정의 - array 필드지만 각 object 내부에서 and 조건을 만족하는 문서만 검색 - ES에서는 성능 최적화를 위하 parent 문서와 child(nested) 문서를 동일 샤드에 저장 | PUT test/_doc/2 {“properties”: { “companies”: [ /* nested 타입 필드 정의 */ { “name”: “test-name1” }, { “name”: “test-name1” } ] } } |
Shard
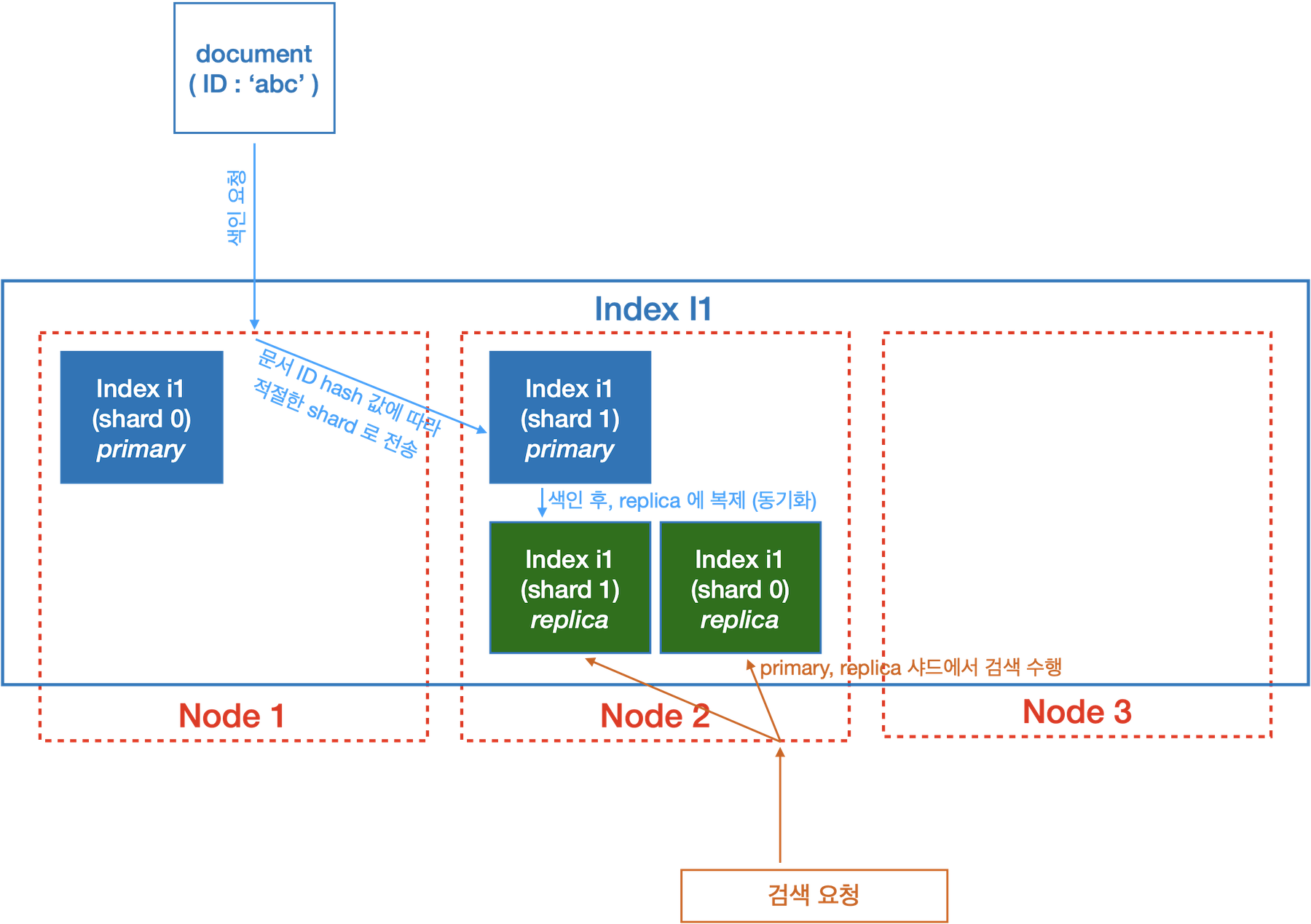
- Node 에서 Node 로 이동되는 가장 작은 단위
- 색인에 대한 데이터를 저장하는 물리적인 파일의 디렉토리
- shard 당 replica 수는 언제든 변경 가능
- primary shard 수는 index 생성 후, 변경 불가 (default : 5개)
Alias
- 인덱스에 alias 를 설정하여 접근 가능
- 외부에서 접근할 때, alias 를 사용하고, 내부적으로 alias 와 index 의 매핑을 필요할 때 변경 가능
- 여러개의 인덱스를 하나의 alias 로 매핑 가능
alias 생성 예제
POST _aliases
{
“actions”: [
{ “add”: { “index” : “{인덱스 이름}”, “alias” : “{alias 이름}” } },
{ “add”: { “index” : “{인덱스 이름}”, “alias” : “{alias 이름}” } },
{ “delete”: { “index” : “{인덱스 이름}”, “alias” : “{alias 이름}” } },
]
}
Snapshot
- 인덱스를 snapshot 으로 백업 기능
- 클러스터 전체를 snapshot 으로 생성가능
- snapshot 파일로 인덱스,데이터를 복구 가능
- elasticsearch.yml 에 설정된 경로에 snapshot 저장됨
path.repo: [ “/home/{경로}/“ ]
- elasticsearch.yml 설정 -> repository 생성 -> snapshot 생성 -> snapshot 에서 데이터 복구
repository 생성
PUT _snapshot/{repository 이름}
{
“type”: “fs”
“settings”: {
“location” : “{snapshot 저장 경로(물리경로)}”,
“compress”: {snaphost 저장시 압축여부 true/false}
“chunk_size”: “{snapshot 파일을 여러파일로 나눌 때 각 파일 크기}”
“max_restore_bytes_per_sec” : “{snapshot 복원 속도 (default: 40MB)}”
“max_snapshot_bytes_per_sec” : “{snapshot 생성 속도 (default: 40MB)}”
“readonly”: “{repository의 readonly 여부}”
}
}
snapshot 생성
PUT _snapshot/{repository 이름}/{snapshot 이름}?wait_for_completion=true
{
“indices”: “{snapshot 생성 대상 인덱스이름}”
… option …
}
snapshot 조회
GET _snapshot/{repository 이름}/_all
snapshot 복원
``` POST _snapshot/{repository 이름}/{snapshot 이름}/_restore ``
[!failure]- Failure SyntaxError: Unexpected token ‘<’, “«««< HE”… is not valid JSON
JSON.parse
plugin:obsidian-textgenerator-plugin:176841 PackageManager.load plugin:obsidian-textgenerator-plugin:176841:33
plugin:obsidian-textgenerator-plugin:179856 async TextGeneratorPlugin.onload plugin:obsidian-textgenerator-plugin:179856:7
댓글남기기