ElasticSearch 살펴보기 - Cluster
ElasticSearch 살펴보기 - Cluster
ES Cluster 구성
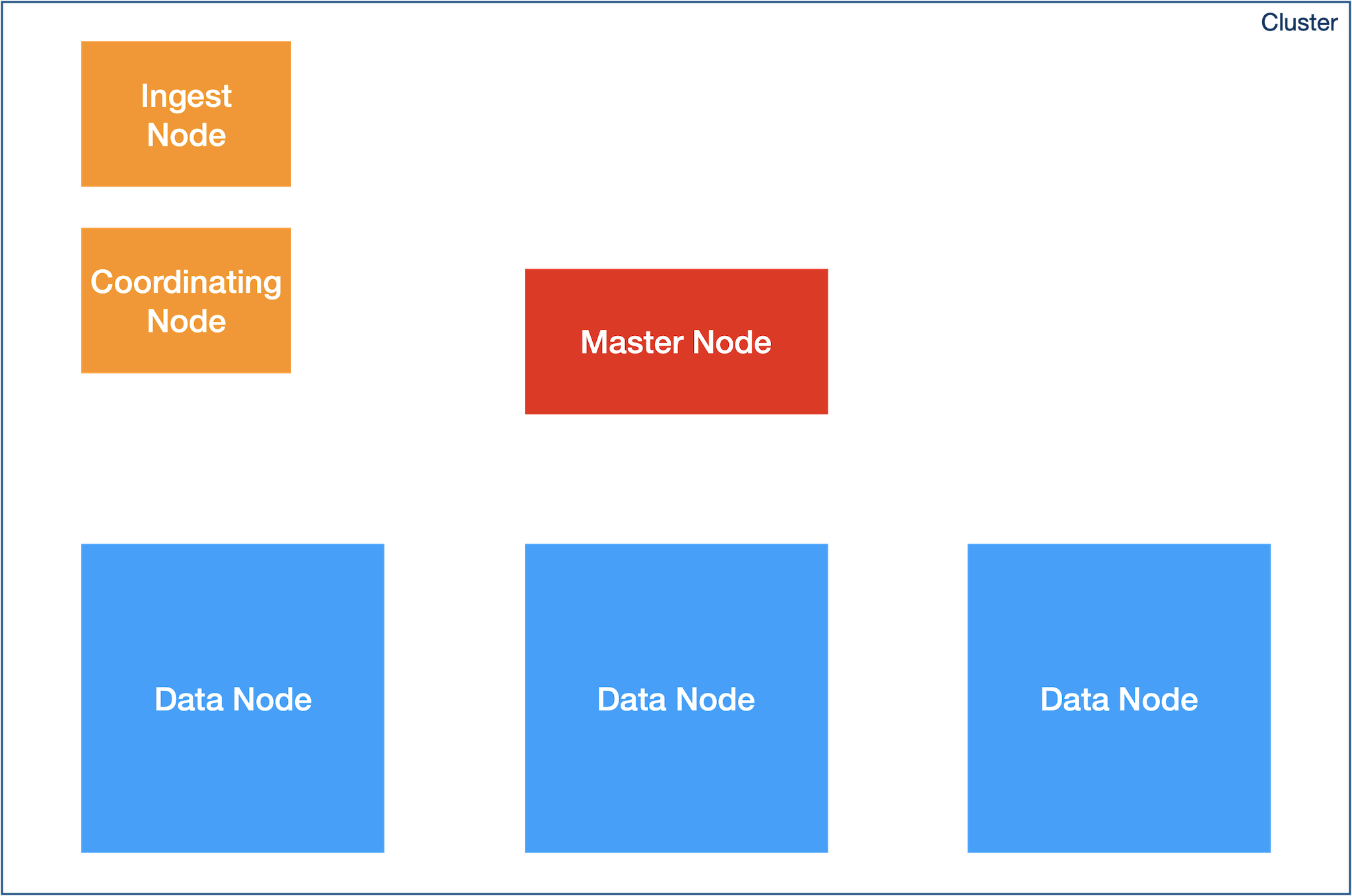
Ingest Node
- 색인 전처리
- 설정
node.ingest: true - 데이터 전처리, 타입 체크, 포맷변환, 유용성 검증
- 안정적 cluster 운영을 위해 물리적으로 분리할 것
Coordinating Node
- 검색/집계의 분산처리
- cross cluster search 를 사용하면, 여러 클러스터의 데이터를 한번에 조회 가능
- 설정
node.master ; false node.data: false node.ingest: false search.remote.connect: false - 사용자 요청 처리
- 사용자의 검색 요청을 클러스터내 모든 데이터 노드에 위임
- 데이터 노드의 검색 결과를 취합
- ES의 모든 노드는 기본적으로 Coordinate 노드
- 안정적 cluster 운영을 위해 물리적으로 분리할 것
- 검색용 Coordinate Node, 색인용 Coordinate Node, 집계용 Coordinate Node 으로 분리 운영 가능
Master Node
- 클러스터 관리/제어
- node, shard 모니터링/관리
- 색인 요청 라우팅
- 검색 요청 부하 분산
- 장애 복구 (replica 를 이용한 shard 복구)
- 설정
node.master: true - 장애 복구 책임
- 인덱스 변경, 삭제
- 클러스터의 노드 모니터링
- 안정적 cluster 운영을 위해 물리적으로 분리할 것
- master 노드로 셋팅된 node 를 최소 3대 이상 운영할 것을 권장 - master node
- fault 시 투표를 통해 새로운 master 가 선출됨 - split-brain 발생하지 않도록
- discovery.zen.minimum_master_nodes 값을 ‘(master 후보 node 수 / 2) + 1’ 로 설정
Data Node
- 데이터 저장, CURD
- 검색, 집계 수행
- 설정
node.data: true - 데이터 보관, CRUD, 검색, 집계
- 고성능 장비 필요
ES Cluster Config/Log
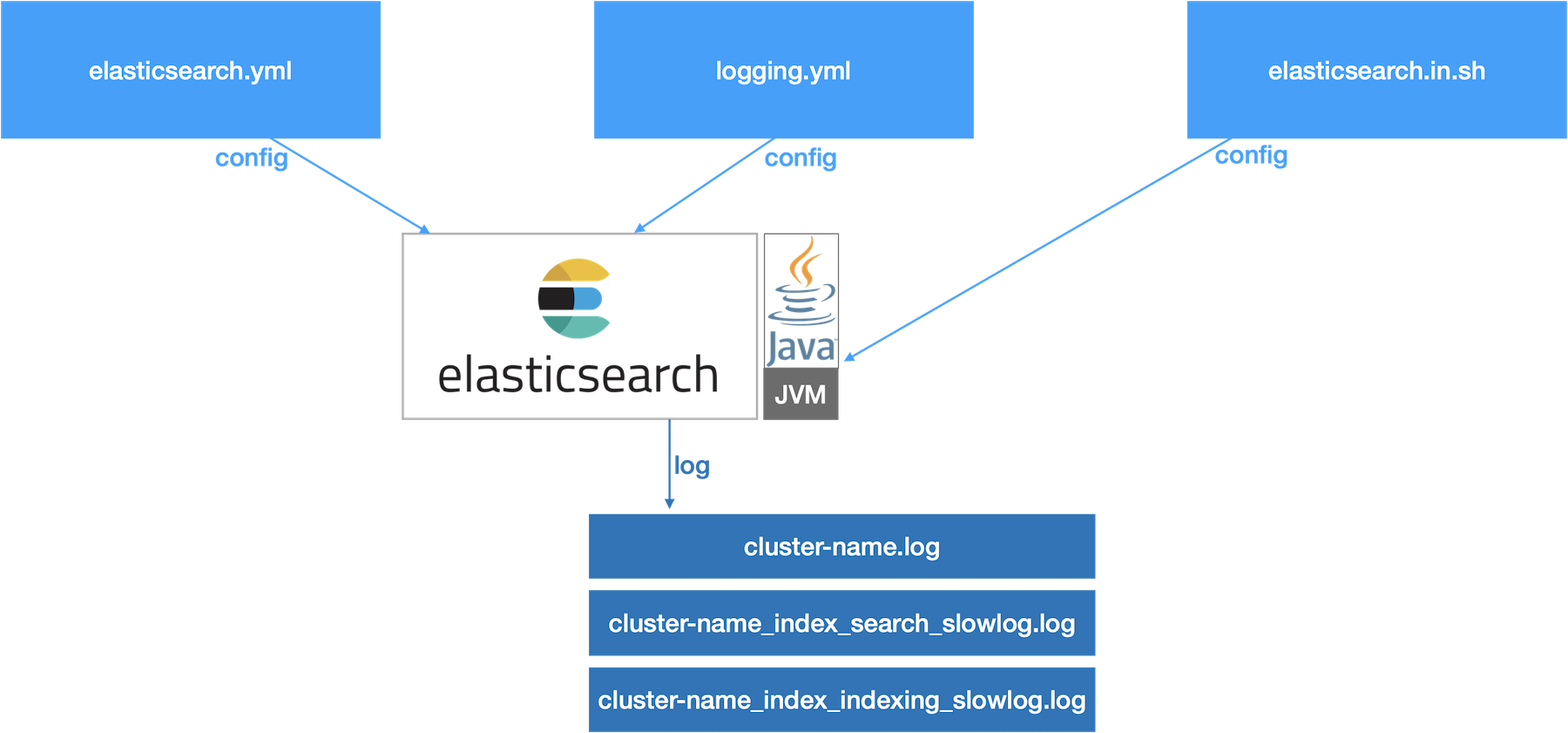
설정파일
elasticsearch.yml: Elastic Search 옵션 설정 파일logging.yml: Elastic Search 자체 log 설정 파일elasticsearch.in.sh: Elastic Search 실행을 위한 JVM 설정
로그파일
cluster-name.log: Query fail, node/cluster 상태 로그cluster-name_index_search_slowlog.log: Slow Query 로그 (default: 0.5s 이상)cluster-name_index_indexing_slowlog.log: Slow 색인 로그 (default: 0.5s 이상)
elasticsearch.yml 주요 설정
| config | |
|---|---|
| action.auto_create_index | 인덱스 자동 생성여부 (default: true, 권장: false) |
| index.mapper.dynamic | 동적 매핑 사용여부 (default: true, 권장: false) - ES 5.x 이상에서는 PUT _all_settings API 로 설정 |
| indices.requests.cache.size | aggregation 에 사용할 캐시크기 지정(ex. 2%) (default : 1%) |
| index.queries.cache.enabled | node query cache 활성화(true/false) 설정 |
| index.number_of_shards | index의 primary shard 개수 default 설정 (index 생성 API에서 조정 가능) - ES 5.x 이상에서는 PUT _all_settings API 로 설정 |
| index.number_of_replicas | index shard 의 replicas 개수 default 설정 (index 생성 API에서 조정 가능) - ES 5.x 이상에서는 PUT _all_settings API 로 설정 |
| bootstrap.memory_lock | mlockall() 과 동일한 방식으로 swap을 최대한 방지 (권장값: true) |
| node.master | master (cluster 관리) 기능 활성화 |
| node.data | data (데이터 CRUD, 검색, 집계) 기능 활성화 |
| node.ingest | ingest (색인 데이터 전처리, 타입체크, 포맷 변경 등) 기능 활성화 |
| search.remote.connect | 외부 클러스터 접속 기능 |
| discovery.zen.minimum_master_nodes | split-brain 발생하지 않도록 discovery.zen.minimum_master_nodes 값을 ‘(master 후보 node 수 / 2) + 1’ 로 설정 |
Performance Tuning
primary shard 개수
- index 생성 시점에 primary shard 개수 설정
- 운영중인 index 의 primary shard 개수 수정 불가
- reindex API (POST _reindex)로 index 를 재생성하며 shard 개수 변경 가능
replica shard 개수
- 운영중인 index 의 replica shard 개수는 언제든 변경 가능
- replica shard 개수 증가 : master node 부하 증가, 색인 성능 저하, 검색 성능 향상
- replica shard 개수 감소 : master node 부하 감소, 색인 성능 증가, 검색 성능 저하
최대 shard 개수
- index 당 shard 를 최대1024개 까지 생성 가능
shard 크기 (용량)
- shard 용량 증가 : 장애 복구시 shard 이동을 위한 네트워크 비용 증가
- shard 용량 감소 : shard 개수가 증가한다면 master node 부하 증가 및 리소스 낭비
최대 문서 개수
- ES shard 내 최대 문서 개수 == Lucene 의 segment 내 최대 저장 가능한 문서 개수
- Lucene 의 segment 내 최대 저장 가능한 문서 개수 : 약 20억 개 (Integer.MAX_VALUE)
- ES index 에 색인 가능한 최대 문서 개수 : - (Lucene 의 segment 내 최대 문서 개수) * (ES 인덱스내 shard 최대 개수) = 20억 * 1024 = 2조
JVM Heap
- 최대 32GB 이하로 설정을 권장 (default: 1GB) - JVM 의 Compressed Ordinary Object Pointer 는 32GB 까지만 효율적으로 동작
- 32GB 이상 heap 이 필요한 경우에는 서버 또는 ES 인스턴스 증설이 효과적
- 머신 memory 의 50%는 OS에 보장해야 함 - lucene segment 는 시스템 cache 를 사용하기 때문
Compressed OOP
- JDK8 이상에서는 default 로 Compressed OOP를 사용
- heap 크기가 32GB 이상 설정되는 경우 (비효율적인) 일반 OOP 방식으로 전환 됨
- Compressed OOP 동작 여부를 확인
java {옵션} -XX:+PrintFlagsFinal -version | grep UseCompressedOops값이 true 인지 확인- JVM 버전/플랫폼마다 Compressed OOP 사용을 위한 32GB의 정확한 기준이 다름
- Compressed OOP 를 안정적으로 적용하려면 31G로 heap 을 설정하는 것도 권장
- Zero-Based Compressed OOP 를 사용하려면 32GB 부터 heap 크기를 줄여가며 Compressed Opps mode 를 확인해봐야함
vm.max_map_count
- Lucene 이 segment 저장에 사용하는 mmap 개수 설정
- Lucene 은 Java NIO 를 사용하여 (JVM을 거치치 않고) 시스템콜 호출
- vm.max_map_count 는 262144 이상값으로 설정해야 함 (시스템 default: 65530)
swap
- swap 비활성호 설정으로 인한 노드 성능저하 방지
- /etc/fstab 파일 수정으로 swap 비활성화
- /proc/sys/vm/swapness 값을 1로 설정하여 swap 발생을 최소화 - elasticsearch.yml 의 bootstrap.memory_lock: true 설정하여 페이징을 금지 및 데이터의 RAM 상주를 강제 (GET _nodes?filter_path=**.mlockall 로 bootstrap.memory_lock 설정되었는지 확인 필요)
Cluster Bootrap 과정
- Node 실행시 설정 오류 등을 검수하는 과정
cluster management API
PUT,GET _cluster/setting- 클러스터 설정을 동적으로 변경
- persistent (영구 적용), transient (일시 적용) 가능
- persistent 적용된 설정은 elasticsearch.yml 보다 우선순위 높음
GET _cluster/pending_tasks- 클러스터를 변경하는 task (index 생성, mapping 수정, shard 재할당 등) 중, 대기중인 목록을 출력
GET _nodes/hot_threads- node 별 cpu 사용률이 높은 thread 목록 출력
POST _cluster/reroute- 특정 node 의 shard 를 다른 node 로 이동
- 네트워크 부하/비용이 큰 작업
GET _tasks?nodes={node name}- 실행중인 task 출력
GET _nodes/usage- 관리용 API (모니터링 API, 상태조회 API, health check API 등) 호출 현황 출력
- 과도한 관리 API 호출 여부를 주기적으로 확인할 것을 권장
댓글 남기기