ElasticSearch 살펴보기 - Aggregation
ElasticSearch의 Aggregation은 데이터를 분산 처리하고, 데이터를 분석하고, 데이터를 정리하는 데 사용됩니다. Aggregation은 인덱스를 활용하여 데이터를 분산 처리할 수 있습니다.
Aggregation의 종류
- Top Hits Aggregation: 가장 높은 스코어를 가진 문서를 반환합니다.
- Cardinality Aggregation: 특정 필드의 중복된 값의 개수를 반환합니다.
- Terms Aggregation: 특정 필드의 값의 개수를 반환합니다.
- Geohash Aggregation: 지리적 위치를 사용하여 데이터를 그룹화합니다.
- Percentiles Aggregation: 특정 필드의 값의 분위수를 반환합니다.
- Sum Aggregation: 특정 필드의 값의 합을 반환합니다.
- Max Aggregation: 특정 필드의 값의 최대값을 반환합니다.
- Min Aggregation: 특정 필드의 값의 최소값을 반환합니다.
- Mean Aggregation: 특정 필드의 값의 평균값을 반환합니다.
- Median Aggregation: 특정 필드의 값의 중간값을 반환합니다.
- Standard Deviation Aggregation: 특정 필드의 값의 표준편차를 반환합니다.
Aggregation의 사용 예
Aggregation은 데이터를 분석하고, 데이터를 정리하는 데 사용됩니다. 예를 들어, 다음은 Aggregation을 사용하여 데이터를 분석하는 예입니다.
- 사용자 정보: 사용자 ID, 이름, 이메일, 주소, 등급을 사용하여 사용자 정보를 분석합니다.
- 상품 정보: 상품 ID, 이름, 가격, 설명, 등급을 사용하여 상품 정보를 분석합니다.
- orders: 주문 ID, 사용자 ID, 상품 ID, 주문 날짜, 등급을 사용하여 주문 정보를 분석합니다.
Aggregation의 장점
Aggregation은 인덱스를 활용하여 데이터를 분산 처리할 수 있습니다. 데이터가 양이 많을 수록 CPU/메모리 사용률이 높아질 수 있습니다. 하지만, Aggregation은 데이터를 분석하고, 데이터를 정리하는 데 사용됩니다. 따라서, Aggregation은 데이터를 분석하고, 데이터를 정리하는 데 사용되는 데이터를 사용하여 최적화할 수 있습니다.
Aggregation의 단점
Aggregation은 데이터를 분석하고, 데이터를 정리하는 데 사용됩니다. 따라서, Aggregation은 데이터를 분석하고, 데이터를 정리하는 데 사용되는 데이터를 사용하여 최적화할 수 있습니다. 또한, Aggregation은 데이터를 분석하고, 데이터를 정리하는 데 사용되는 데이터를 사용하여 최적화할 수 있습니다. 따라서, Aggregation은 데이터를 분석하고, 데이터를 정리하는 데 사용되는 데이터를 사용하여 최적화할 수 있습니다.
Aggregation의 예시
Aggregation은 다음의 예시를 사용하여 데이터를 분석하고, 데이터를 정리할 수 있습니다.
GET /myindex/_search
{
"aggs": {
"user_info": {
"terms": {
"field": "user_id"
}
},
"product_info": {
"terms": {
"field": "product_id"
}
},
"order_info": {
"terms": {
"field": "order_id"
}
}
}
}
이 예시에서는 Aggregation을 사용하여 사용자 ID, 상품 ID, 주문 ID를 사용하여 데이터를 분석하고, 데이터를 정리합니다. Aggregation은 데이터를 분석하고, 데이터를 정리하는 데 사용되는 데이터를 사용하여 최적화할 수 있습니다.
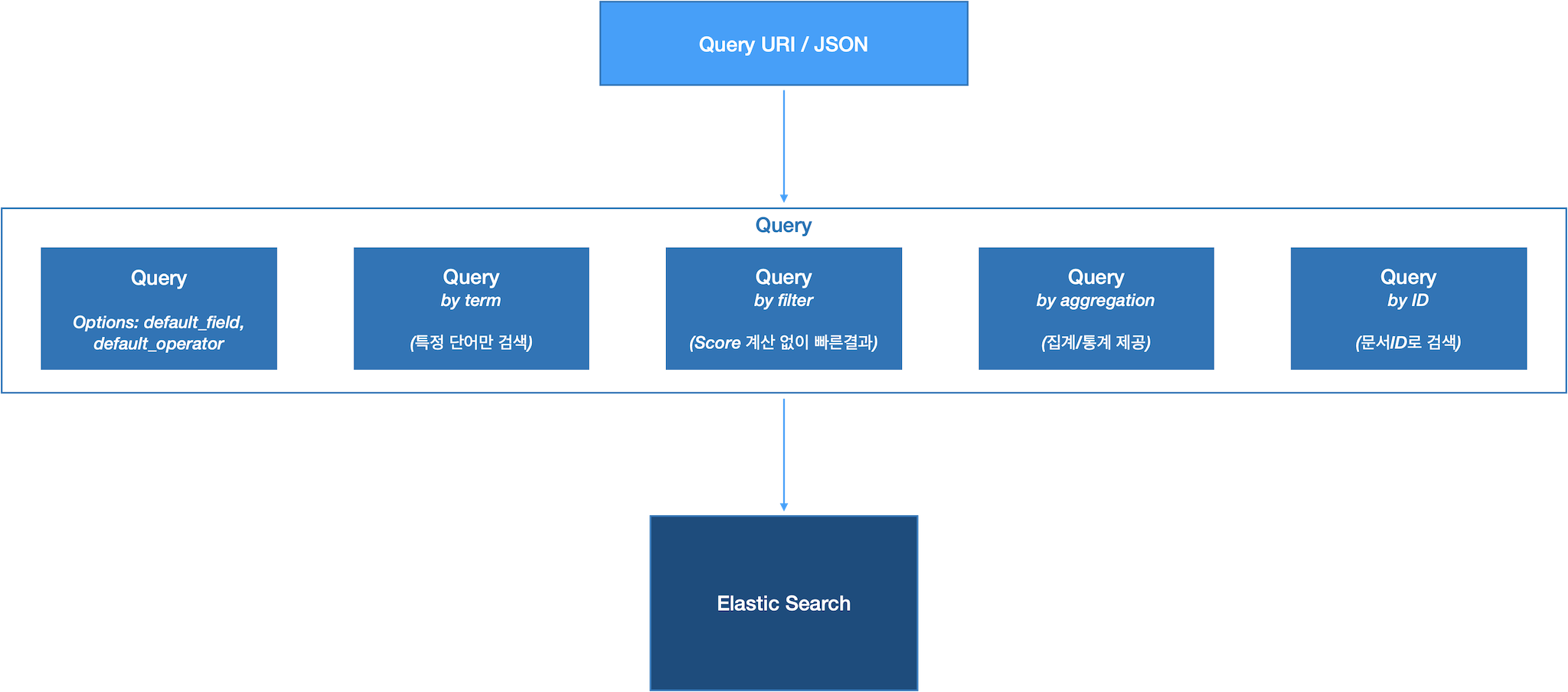
| ES cache 종류 | |
|---|---|
| node query cache | - 노드내 모든 샤드가 공유 - LRU 캐시 - elasticsearch.yml 에 ’index.queries.cache.enabled: true’ 설정하여 캐시 활성화 |
| shard request cache | - 샤드에서 수행된 쿼리 결과를 캐싱 - 샤드의 내용이 변경되면 캐시가 삭제됨 -> 업데이트가 많은 샤드에서는 shard request cache 적용이 성능 저하를 유발 |
| field data cache | aggregation 동인 필드 값을 메모리에 캐시 |
Aggregation API 동작 실행 방식
쿼리 수행 결과에 대해 aggregation 결과 수행
"query" : { ... } // 생략시 match._all
"aggs" : { ... }
}

- bucket : 쿼리 결과로 grouping 된 문서들의 모음
분산환경에서 Aggregation 동작 방식
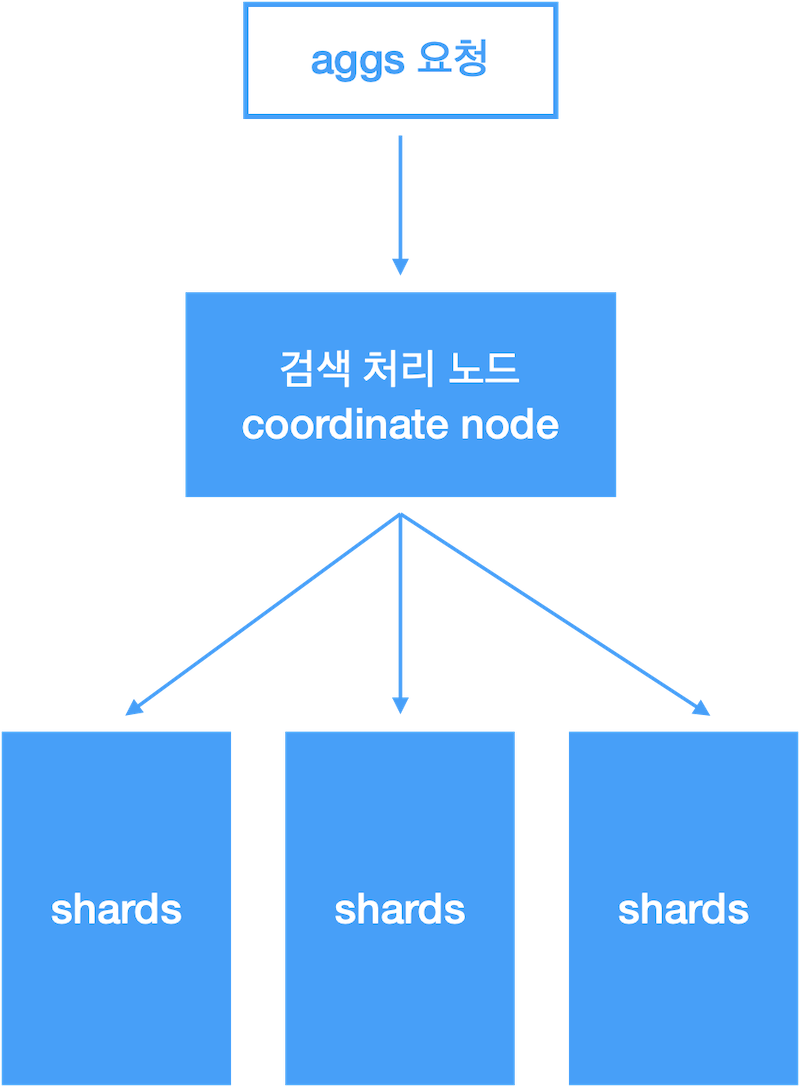
- coordinate node 는 각 shard 결과를 취합해서 size 만큼 최종결과 반환
- 각 shard 에 shard_size 크기만큼 1차 집계 결과 요청
- shard_size 외 결과는 누락되며, 최종 결과의 정확도에 영향
Aggregation Query Request / Response 예제
Request
{
"query" : { ... } // 생략시 match._all
"aggs" : {
"<aggregation_name1>": {
"<aggregation_type>": {
"field": "{필드명}"
}
}
[,"meta": { [<meta_data_body>] } ]?
[,"aggregations": { [<sub_aggregations>] } ]?
"<aggregation_name2>": {
"global": {}, // (bucket 외에) 전체 문서에 대해서 aggregation 수행할 때 설정
"aggs": {
"<sub_aggregation_name1>": {
"<sub_aggregation_type>": {
"field": "{필드명}"
}
}
}
}
}
}
Response
{
"took" : 2, // 소요시간
"timed_out" : false, // timeout 발생 여부
"_shards" : { // 검색에 영향 받은 shard 정보
"total": 5, // - 영향받은 shard 총 개수
"success": 3, // - 검색이 처리된 shard 개수
"skipped": 2, // - 검색이 처리되지 않은(skip) shard 개수
"failed": 0, // - 검색이 처리 실패한 shard 개수
},
"hits": { // 검색 결과
"total": 100, // 검색 쿼리가 일치한 문서 총 개수
"max_score": 100, // 검색 결과에 포함된 문서의 score 최대값
"hits": {} // 검색 결과 문서 목록 (default: 10개만 반환)
}
"aggregations" : {
"<aggregation_name>": {
// 집계 결과
}
}
}
Metric Aggregation
- 특정 필드에 대한 sum, avg, sort, geo_bounds 계산
- (검색 결과 출력 없이) 집계 결과만 출력해야하는 경우 (size=0 으로 쿼리)
- ex.
GET {인덱스명}/_search?size=0
- ex.
- 집계 연산간 각 문서에 대해 적용될 script 작성 가능
- query 작성시 constant_score 를 사용하여, score 값을 계산하지 않도록 해서 성능 최적화
| Metric Aggregation 종류 | |
|---|---|
| single-value | - 결과 값이 단일값 - sum, avg 등 |
| multi-value | - 결과 값이 여러개가 될 수 있음 - stats, geo_bounds |
예시) 아래래 예제에서는 avg 집계를 사용하여 모든 주문의 평균 total_price를 계산합니다. size를 0으로 설정하여 검색 결과에서 문서를 반환하지 않고 집계 결과만 반환합니다.
POST /orders/_search
{
"size": 0, // 문서 결과를 반환하지 않음
"aggs": {
"average_price": {
"avg": {
"field": "total_price"
}
}
}
}
Bucket Aggregation
- metric 계산없이 bucket 생성
- bucket 집계 결과로 bucket 을 만들고 계속 중첩된 집계 가능
- 중첩이 많을 수록 메모리 사용률 증가
- ES에 최대 허용 bucket 수 제한 있음 ( search.max_buckets 에 설정 가능)
- bucket
- 집계된 결과 데이터
- 메모리에 저장
Bucket Aggregation 동작 방식
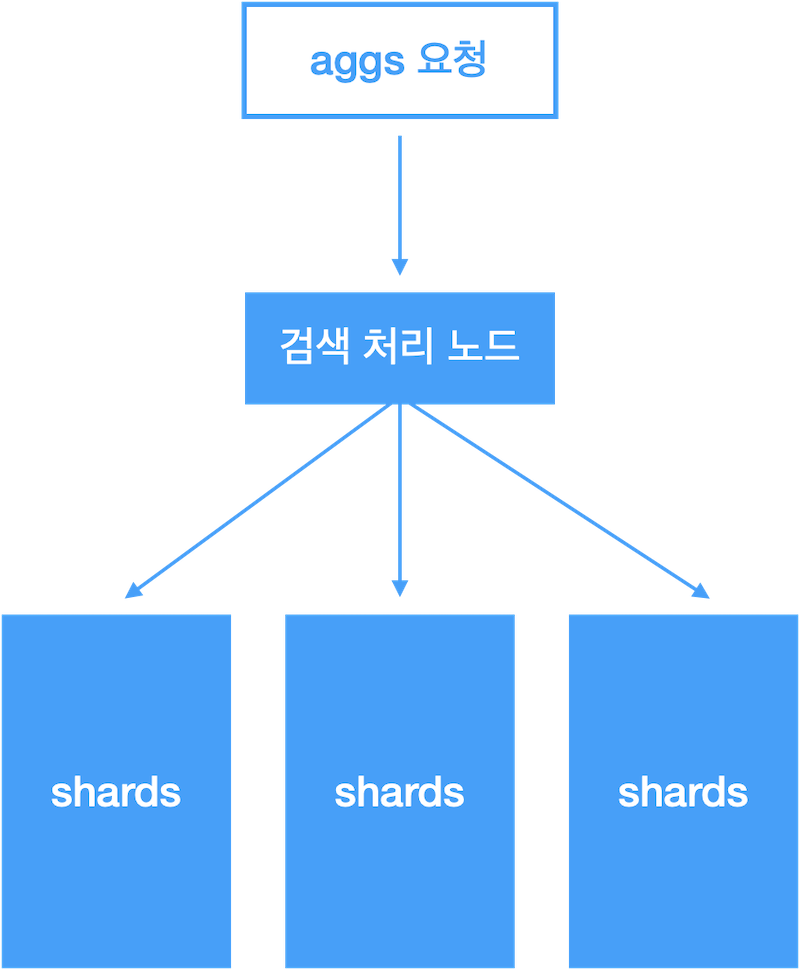
- 검색 처리 노드에서 각 shard 결과를 취합해서 size 만큼 최종결과 반환
- 각 shard 에 shard_size 크기의 집계 결과 요청
- shard_size 외 결과는 누락되며,최종 결과의 정확도에 영향
예제) 아래 예제에서는 terms 집계를 사용하여 status_code 필드의 값에 따라 문서를 그룹화합니다. 각 그룹(버킷)은 고유한 status_code 값을 가지며, 그룹 내 문서 수를 계산합니다. size 매개변수는 반환할 최대 버킷 수를 지정합니다.
POST /logs/_search
{
"size": 0, // 문서 결과를 반환하지 않음
"aggs": {
"status_code_buckets": {
"terms": {
"field": "status_code",
"size": 10 // 상위 10개의 가장 흔한 상태 코드를 반환
}
}
}
}
댓글남기기